
So far, each variable has stored exactly one value. In practice, we constantly work with groups of values that belong together, such as coordinate pairs, lists of cities, or sets of unique IDs.
In this section, you will learn how Python stores multiple values in one variable (often called collections or data structures) and how to choose the right one for your spatial workflows.
1. The Four Built-in Collections¶
Python provides four built-in collection types that we will use throughout the course:
| Collection | Brackets | Key property | Example |
|---|---|---|---|
| List | [ ] | ordered and changeable | ["Bari", "Harare", "Manila"] |
| Tuple | ( ) | ordered and fixed | (14.6007, 120.9746) |
| Set | { } | unordered and unique values | {"Asia", "Africa"} |
| Dictionary | { } | named key-value pairs | {"name": "Bari", "population": 315473} |
Choosing the right collection type improves the clarity and correctness of your code.
2. Lists: Ordered and Changeable¶
Lists store ordered sequences of values. They are the workhorse data structure in Python, ideal for data where sequence matters or where values grow and change over time.
cities = ["Bari", "Harare", "Manila"]Lists:
are written using square brackets
[]preserve order
allow duplicate values
are mutable, meaning their contents can change
A Geoscience Example Dataset¶
We will work with a simple list of elevations in meters measured along a hiking transect.
elevations_m = [450, 470, 515, 560, 545, 580]Each value represents the elevation at a measurement point. The order reflects the order along the transect.
Accessing List Elements (Indexing)¶
List items are accessed by their numeric index position, always starting at 0. You can also count backward from the end using negative indexing.
print(elevations_m[0]) # First item: 450
print(elevations_m[-1]) # Last item: 545
Indexing allows you to retrieve individual values from a sequence.
Slicing Lists¶
Slicing lets you extract a range of values.
elevations_m[1:4]This returns a new list containing items at indices 1, 2, and 3.
Some useful slicing patterns:
elevations_m[:3] # first three values
elevations_m[3:] # values from index 3 to the endSlicing is useful for working with segments of a profile or time series.
Changing List Values¶
Lists are mutable, meaning you can change them after they are created.
# Replace a specific value
elevations_m[2] = 520The value at index 2 is replaced.
The list keeps its length and order.
You can also replace multiple values at once using slicing.
elevations_m[3:5] = [565, 550]This updates a range of values in place.
Adding Items to a List¶
Lists can grow dynamically.
To add an item at the end, use append().
elevations_m.append(600)To insert an item at a specific position, use insert().
elevations_m.insert(1, 460)To add multiple items at once, use extend().
new_measurements = [610, 625]
elevations_m.extend(new_measurements)You can also combine two lists using +.
all_elevations = elevations_m + [640, 655]elevations_m.remove(460)This removes the first matching value.
Remove an item by position:
elevations_m.pop(2)If no index is given, pop() removes the last item.
elevations_m.pop()You can also delete items using del.
del elevations_m[0]len(elevations_m)This is useful when looping over data or validating inputs.
Sorting and Reordering Lists¶
Lists can be sorted in place.
elevations_m.sort()To sort in reverse order:
elevations_m.sort(reverse=True)You can also reverse the current order without sorting.
elevations_m.reverse()Sorting is useful for summaries. Reversing is useful when order already has meaning.
Copying Lists¶
Assigning a list to a new variable does not create a copy.
a = elevations_mBoth variables now refer to the same list.
To create an independent copy, use copy().
b = elevations_m.copy()Now changes to b do not affect elevations_m.
Key Takeaway for Lists¶
Lists are the right choice when:
order matters
values may change
data grows or shrinks
you work with sequences such as profiles, routes, or time series
They are the workhorse data structure in Python and will appear throughout the course.
3. Tuples: Ordered and Fixed¶
Tuples look like lists, but with one crucial difference: their contents cannot be changed after creation.
Tuples are used when values represent a single logical entity that should remain protected. A very common example in geospatial work is a coordinate pair or a bounding box.
manila_coords = (14.6007, 120.9746)Once created, the values inside a tuple stay the same.
When Tuples Are the Right Choice¶
Use tuples when:
values represent a single logical entity
the order matters
the values should not change accidentally
Examples include:
latitude and longitude pairs
bounding box corners
fixed parameters passed to functions
Tuples make your intention clear: this group of values is not meant to change.
Accessing Tuple Elements¶
Tuple elements are accessed using indexing, just like lists.
latitude = manila_coords[0]longitude = manila_coords[1]Important points:
indexing starts at
0order is preserved
negative indexing also works
manila_coords[-1]The behaviour is the same as for lists.
Immutability in Practice¶
Because tuples are immutable, you cannot change their elements.
manila_coords[0] = 14.7This raises a TypeError.
Python protects the tuple from being modified.
Tuple Unpacking¶
Tuples can be “unpacked” into separate variables in a single, highly readable step:
lat, lon = manila_coords
This assigns:
latto the first valuelonto the second value
Tuple unpacking is very common in:
coordinate handling
function return values
structured data processing
It improves readability and avoids manual indexing.
Combining Tuples¶
Tuples can be combined using the + operator.
bbox_min = (14.5, 120.9)
bbox_max = (14.7, 121.1)
bbox = bbox_min + bbox_maxThis bounding box example creates a new tuple. The original tuples remain unchanged.
Duplicates and Order¶
Like lists, tuples:
preserve order
allow duplicate values
repeated_coords = (0, 0, 1, 1)The difference is not what they store, but whether they can be changed.
The List Workaround¶
Sometimes you start with a tuple but later realise it needs to change. The standard workaround is:
convert the tuple to a list
modify the list
convert it back to a tuple
colors = ("red", "green", "blue")
temp = list(colors)
temp.append("yellow")
colors = tuple(temp)This creates a new tuple with updated values.
Key Takeaway for Tuples¶
Tuples are the right choice when:
order matters
values belong together
the data should not change
you want to protect important values
In geospatial workflows, tuples are especially common for coordinates, fixed parameters, and return values from functions.
Lists and tuples look similar, but choosing between them communicates intent and helps prevent errors later.
4. Sets: Unique Values Only¶
Sets store unique values and do not preserve order. They are designed for one main purpose: answering the question, “Is this value present or not?”
Sets are written using curly brackets {}.
regions = {"Asia", "Africa", "Asia"}Even though "Asia" appears twice, it is stored only once.
What Makes Sets Different¶
Sets are:
unordered
mutable as a collection
free of duplicates
This makes them fundamentally different from lists and tuples.
A set is not a sequence. It is a collection of unique elements.
When Sets Are the Right Choice¶
Use sets when:
you care about uniqueness
duplicates should be ignored automatically
order is irrelevant
you want fast membership checks
Typical geospatial examples include:
land cover classes in a raster tile
unique region names in a dataset
distinct sensor IDs or station codes
unique coordinate reference systems used in a project
Creating Sets¶
Sets are written using curly brackets {}.
land_covers = {"forest", "water", "urban"}A set can contain any data type and can also mix types, although this is rarely useful in practice.
mixed_set = {1, "river", 3.14}Creating a Set from Another Collection¶
A very common pattern is to create a set from a list or tuple to remove duplicates.
messy_list = ["forest", "water", "urban", "water", "forest"]
unique_classes = set(messy_list)
Fast Membership Testing¶
One of the main strengths of sets is checking if a value exists. This is much faster in a set than in a list.
"water" in unique_classes # Returns True
No Indexing!¶
Because sets do not preserve order, they do not support indexing. This attempt will fail:
regions_set[0]To access values, you must iterate.
for land_cover in unique_classes:
print(land_cover)The order of printed values may vary.
Updating Sets¶
Although individual items cannot be modified, items can be added or removed.
Add a single item:
regions_set.add("Oceania")Add multiple items from another collection:
new_regions = {"Antarctica", "Europe"}
regions_set.update(new_regions)The update() method works with lists, tuples, or other sets.
Removing Items¶
Items can be removed using either remove() or discard().
regions_set.remove("Europe")If the item does not exist, remove() raises an error.
regions_set.discard("Mars")discard() does nothing if the value is missing.
Key Takeaway for Sets¶
Sets are the right choice when:
uniqueness matters
order does not
you want fast membership tests
duplicates should be ignored automatically
In geospatial workflows, sets are ideal for categories, labels, IDs, and classes.
If you catch yourself wanting to index a set or care about order, switch to a list or tuple instead.
5. Dictionaries: Named Values¶
Dictionaries store data as key-value pairs. They are ideal when values belong together but should be accessed using meaningful names rather than numeric positions.
city_info = {
"name": "Bari",
"population": 315473,
"coordinates": (41.1311, 16.8701),
}Each key describes what the value represents. This makes dictionaries easier to read and less error prone than collections that rely on positions.
How to Think About Dictionaries¶
A dictionary answers the question:
Given this name, what is the corresponding value?
Unlike lists or tuples, dictionaries do not store values in a sequence. They store associations.
This is why dictionaries are sometimes described as lookup tables or hash maps.
Typical Geoscience Use Cases¶
Dictionaries are common in geospatial work when handling:
attributes of a city, station, or feature
metadata of a dataset
configuration settings
results returned from an API
records from a table where each column has a name
For example, a weather station record:
station = {
"id": "CH-BRN",
"name": "Bern",
"elevation_m": 540,
"temperature_C": 12.4,
}Accessing Dictionary Values¶
Dictionary values are accessed using their keys, written in square brackets.
city_info["name"]city_info["population"]This avoids the need to remember index positions, which is required for lists and tuples.
Keys and Values¶
Important rules for dictionary keys:
keys must be unique
keys are usually strings
keys cannot be changed once created
values can be changed freely
Values can be of any type, including:
numbers
strings
tuples
lists
even other dictionaries
city_info["districts"] = ["Murattiano", "Japigia", "Libertà"]city_info["area_km2"] # KeyErrorTo avoid this, use get().
city_info.get("area_km2", "not available")If the key exists, its value is returned.
If not, the default value None is returned instead.
This pattern is especially useful when working with:
incomplete datasets
optional attributes
external data sources
Modifying Dictionary Values¶
You can update values by assigning to an existing key.
city_info["population"] = 320000You can also add new key value pairs the same way.
city_info["area_km2"] = 116Updating Multiple Values with update()¶
The update() method allows you to change or add multiple entries at once.
city_info.update(
{
"population": 321000,
"country": "Italy",
}
)city_info.pop("area_km2")The value is removed and returned.
To remove the most recently added item (Python 3.7+):
city_info.popitem()To remove everything from a dictionary:
city_info.clear()city_info.keys() # returns all dictionary keys (e.g. "name", "population")city_info.values() # returns all stored values (e.g. attributes for each city)city_info.items() # returns key–value pairs as tuples (key, value)These return views of the dictionary and are often used when looping. You will work with these more in the section on loops.
Dictionaries vs Lists¶
Dictionaries differ fundamentally from lists.
| Lists | Dictionaries |
|---|---|
| Values are accessed by position | Values are accessed by name |
| Order matters | Order does not define meaning |
| Inserting shifts indices | Keys remain stable |
| Best for sequences | Best for structured records |
This makes dictionaries the natural choice for attribute data.
Key Takeaway for Dictionaries¶
Use dictionaries when:
values belong together conceptually
each value has a clear meaning
access by name is safer than access by position
you are modelling real world objects or records
In geospatial programming, dictionaries are the backbone of feature attributes, metadata, and configuration.
If you find yourself remembering numbers like data[3] or data[7], a dictionary is usually the better choice.
6. Indexing and Referencing¶
To work with values stored inside collections, Python uses indexing and referencing.
All collections use square brackets, but what goes inside the brackets depends on the collection type.
Numeric indexing for lists and tuples¶
Lists and tuples store values in a fixed order.
You access elements by their position, starting at index 0.
cities[0]cities[-1]The first example returns the first element. The second example returns the last element.
Tuples work exactly the same way.
Key based access for dictionaries¶
Dictionaries do not use numeric positions. Instead, values are accessed using keys.
city_info["coordinates"]The key describes what you want, which makes dictionary access explicit and readable.
Sets do not support indexing¶
Sets do not preserve order. Because of this, you cannot access set elements by index.
This will not work:
# regions[0]Sets are designed for membership testing, not positional access.
Multi dimensional collections¶
Collections can contain other collections. This is called nesting.
A common example is a list of lists.
grid = [
[1, 2, 3],
[7, 8, 9],
[6, 5, 4],
]This structure has two levels:
the outer list contains rows
each inner list contains values
Indexing across multiple levels¶
Indexing works one level at a time, from left to right.
grid[1]This returns the second inner list:
[7, 8, 9]You can then index into that list.
grid[1][0]This returns:
7The logic is:
grid[1]selects the second row[0]selects the first value in that row
Each index always starts at 0, at every level.
Thinking in dimensions¶
A collection with:
one level is one dimensional
two levels is two dimensional
three levels is three dimensional
For example:
list of values → one dimensional
list of coordinate pairs → two dimensional
list of time steps, each with a grid → three dimensional
You do not need special syntax. You just apply indexing repeatedly.
Understanding how indexing and referencing work is essential when handling spatial data, tables, and collections of coordinates. It allows you to retrieve exactly the value you intend to work with.
7. Copying vs Referencing Collections¶
How assignment works depends on what kind of value you are working with.
This difference is subtle but very important, and it is a common source of confusion and bugs.
Single values are copied¶
With single item values such as numbers or strings, assignment creates a copy.
a = 5
b = aAfter this:
aandbstore the same valuechanging one does not affect the other
Single values behave independently.
Strings behave the same way.
Even though a string contains multiple characters, it is immutable, so assignment behaves like copying.
s1 = "abc"
s2 = s1Changing one string variable does not affect the other.
Collections are assigned by reference¶
With collections, assignment does not create a copy. Instead, both variables point to the same object in memory.
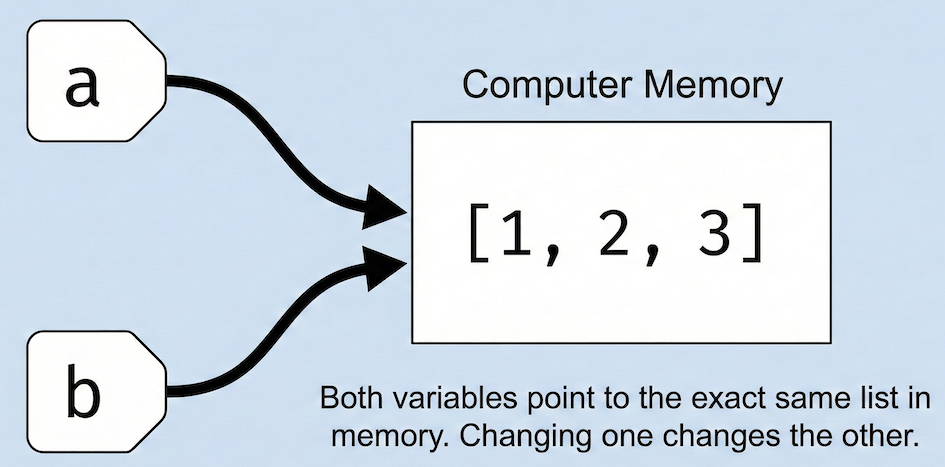
Unlike simple numbers, lists are assigned by reference. Variables act as labels pointing to the same shared object in memory.
list_a = [1, 2, 3]
list_b = list_a
# Modify the original list
list_a.append(4)
# The "second" list changed too!
print(list_b) # Output: [1, 2, 3, 4]
Both lists show the updated content.
This behaviour applies to:
lists
dictionaries
sets
Why this happens¶
Collections are mutable objects. Python avoids copying them automatically to save memory and time.
The consequence is that changes made through one variable are visible through all variables that reference the same object.
This is efficient, but it requires careful thinking.
Equality vs identity¶
Two variables can:
have the same value
refer to the same object
or both
The equality operator == compares values.
The identity operator is checks whether two variables refer to the same object.
a = [1, 2]
b = a
a == ba is bNow compare this with a copy:
c = a.copy()
c == ac is aKey idea:
use
==to compare valuesuse
isto check whether two variables point to the same object
Making an independent copy¶
If you want a separate copy of a collection, you must create it explicitly.
b = a.copy()You can also use the collection constructor.
b = list(a)Both approaches create a new list with the same content.
Now changes to one list do not affect the other.
a.append(4)abUnderstanding copying versus referencing is essential when working with collections of coordinates, attributes, or observations. It helps you avoid unintended side effects and keeps your workflows predictable.
8. Short Exercise¶
You have received raw field information and need to organise it into the appropriate data structures so it can be used reliably later.
Given Data¶
raw_cities = ["Bari", "Harare", "Manila", "Harare"]
coords = (41.1311, 16.8701)
raw_attributes = {
"station": "Bari",
"elevation_m": 315,
"crs": "EPSG:4326",
# Note: "discharge_m3s" is missing
}
Task¶
Create a set called
unique_citiesfromraw_citiesto remove duplicates.Convert that set back into a sorted list called
cities_sorted(Hint: usesorted(unique_cities)).Build a final dictionary called
station_recordwith the following keys:
"name"→ extract this fromraw_attributes"coordinates"→ the coordinate tuple"cities"→ the sorted list you just made"discharge_m3s"→ extract this fromraw_attributesusing.get(), defaulting to"not available"
Use an f-string to print the station name and its latitude (index
0of the coordinate tuple) from your new dictionary.
Sample solution (click to expand)
# 1 & 2) Remove duplicates and sort
unique_cities = set(raw_cities)
cities_sorted = sorted(unique_cities)
# 3) Build a structured station record
station_record = {
"name": raw_attributes["station"],
"coordinates": coords,
"cities": cities_sorted,
"discharge_m3s": raw_attributes.get("discharge_m3s", "not available")
}
# 4) Extract and print from the structured dictionary
lat = station_record["coordinates"][0]
name = station_record["name"]
print(f"Station {name} is located at latitude {lat}.")9. Summary¶
After completing this section, you should understand that:
Lists (
[]) are ordered and changeable.Tuples (
()) are ordered and permanently fixed.Sets (
{}) store unique values and ignore duplicates.Dictionaries (
{key: value}) store data using named labels instead of numeric index positions.Collections are referenced, not copied. Assigning a list to a new variable just creates a second name tag for the same data in memory.
What Comes Next¶
So far, you have learned how to store and access single and multiple values. However, doing calculations manually on every item in a list of 10,000 coordinates is impossible.
In the next lesson (after the practical), we will introduce Loops and Conditional Logic, which will allow your code to automate tasks, make decisions, and process massive lists of data in milliseconds.